对应用系统来讲,为提升系统整体性能与并发度,通常会采取为系统添加基于内存的存储系统方案。由该存储系统充当缓存(本文余下内容会采用“缓存 / Cache”指代此类存储系统),实现对应用系统整体的性能提升,并带来更高的并发表现。
通常在引入缓存后,加上以数据库为代表的数据存储系统,势必会导致系统内存在两个数据存储系统。因为两个数据存储系统的存在,从架构上便构成了主从架构。因为数据需要在两个副本之间传递复制,这一行为带来了数据一致性挑战。面对主从副本数据一致性解决方案主要分为两类,分别属于 强一致性解决方案 和 弱一致性解决方案 。
本文接下来讨论的方案属于弱一致性,对于弱一致性而言,最简单的解决方式是对所有非主副本的数据变更,均通过对主副本拷贝来实现。
如果你是一名有经验的工程师,对于缓存与数据库一致性方案一定听说过 Cache-Aside Pattern ,该模式以数据库做为数据的主副本,同时也是应用系统广泛采纳的设计方案。Cache-Aside 模式不会主动将数据复制到缓存中,而是在缓存未查询到数据时,从数据库复制到缓存中,所以又名 Lazy Loading 模式。
除此以外,你可能也听过 Read-Through 与 Write-Through 两种模式。这两种模式依赖缓存系统的能力,通过缓存系统内置能力实现对数据库的查询与更新操作,而应用系统无需关心对数据库的变更,只与缓存打交道。在应用系统视角下好像数据库不存在一样,将缓存看作是数据主副本。但现实往往未必如此理想,所以在本专栏文章中给出的系统设计方法,会避免技术与组件的特性,尽可能做到技术中立。
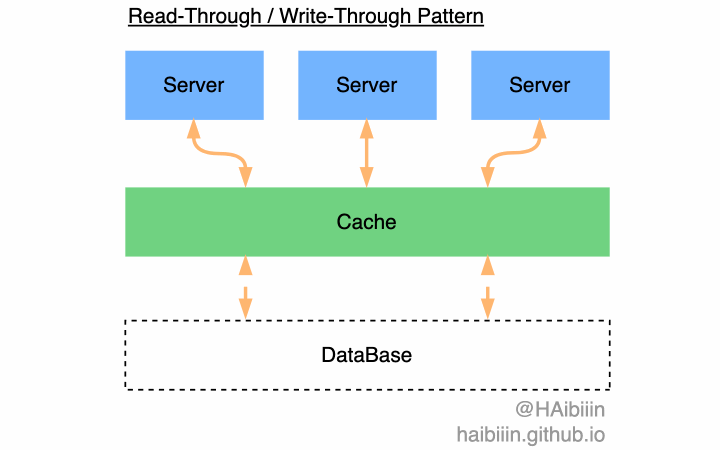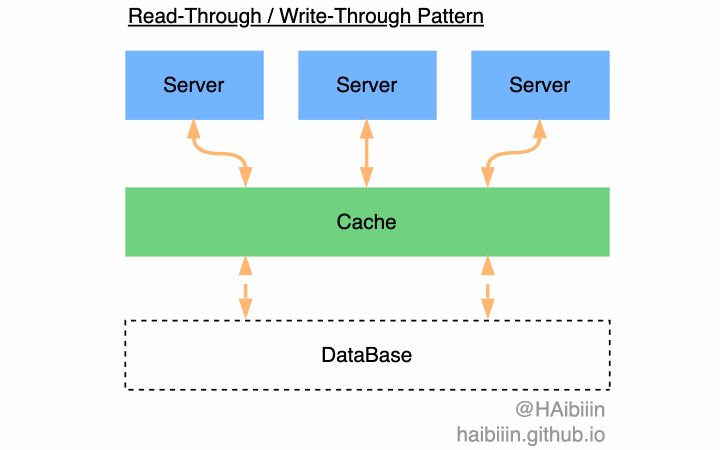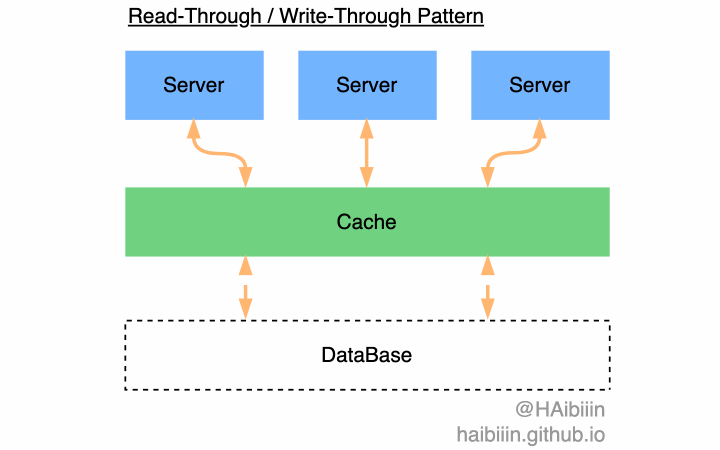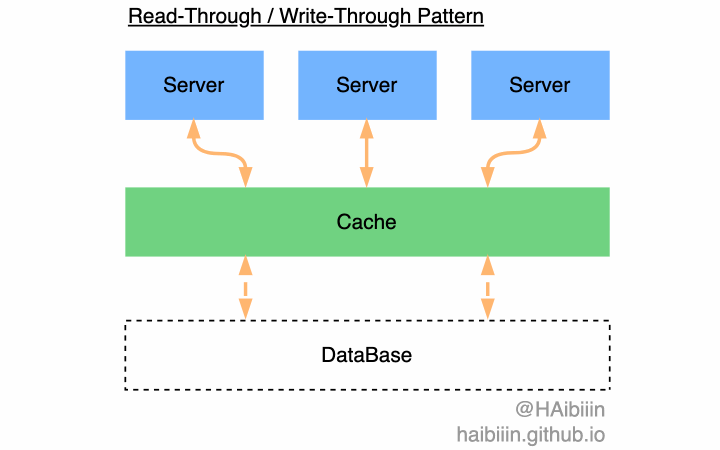
在实现 Cache-Aside 模式的方案中,主要争议点在数据变更场景(数据变更存在三种,分别是数据的新增、修改和删除)下数据同步到缓存的方式。两种方式最核心的区别是数据复制到缓存的时机不同。 一种会主动清理缓存中数据,依赖于数据查询时从数据库复制到缓存中。另一种会主动将数据复制到缓存中,确保数据常驻缓存。
# Cache-Aside 模式下数据读取方式
在探讨两种数据变更方式之前,我们先熟悉一下 Cache-Aside 模式下数据读取的方式。其执行过程如下:
- 当对某条数据记录的查询请求到来时,应用服务先确认该数据记录是否存在于缓存中;
- 如果数据记录在缓存中则直接返回查询结果;
- 如果数据记录不在缓存中,则查询主副本(数据库)获取该数据记录;
- 将主副本数据记录复制到缓存中,并返回该数据记录的查询结果。
结合下图与下方的注释说明,可以进一步直观的理解数据读取时的的过程。
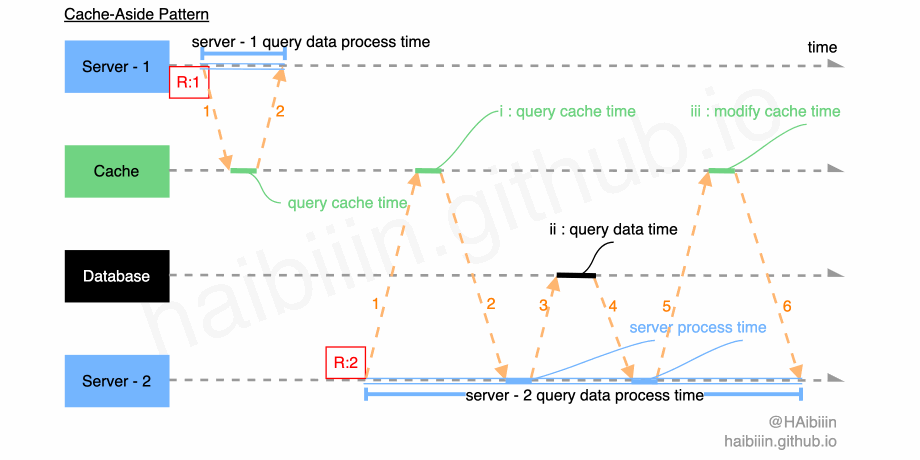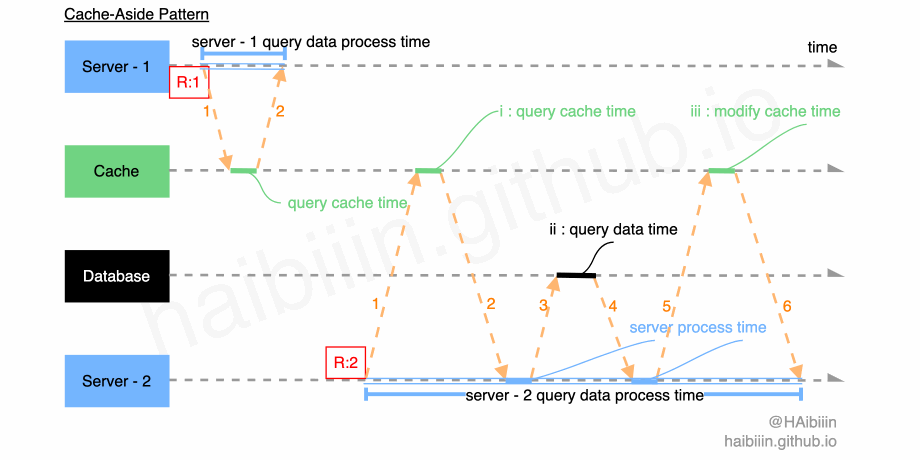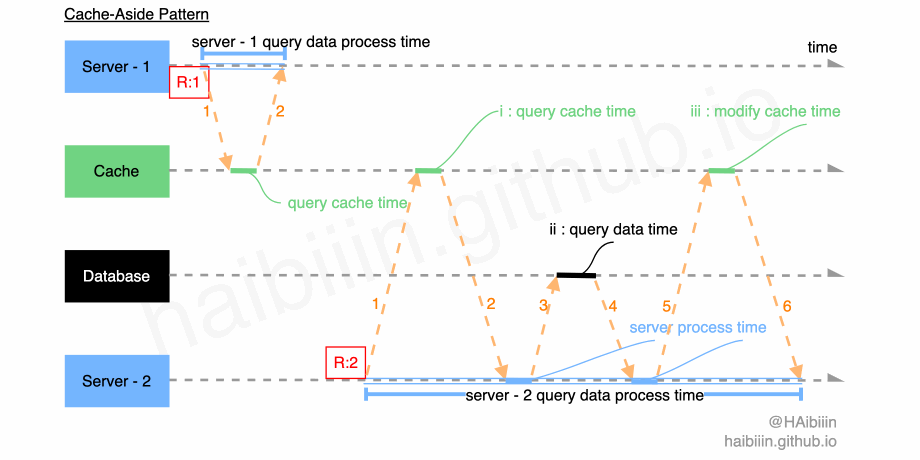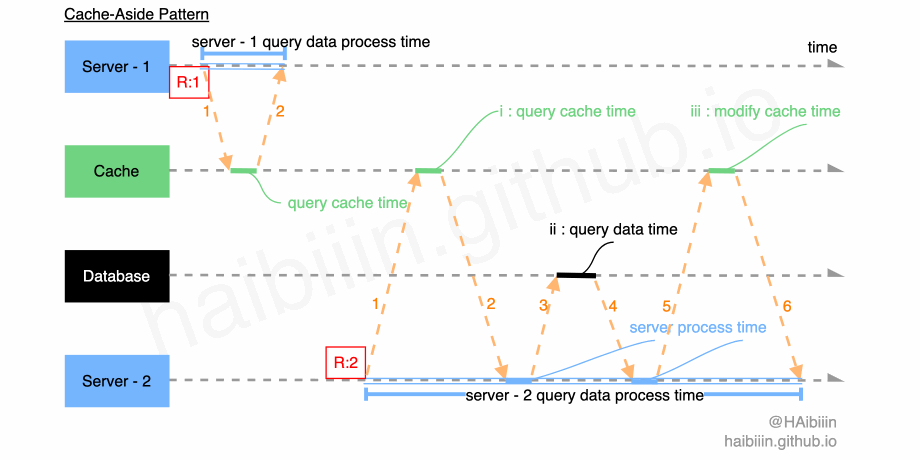
如上图所示我们通过 Server - 1 与 Server - 2 两个应用服务来分别说明两种数据读取场景(本文中的配图均会采取此种表示,后续对于相同内容不再赘述):
- 缓存中存在查询记录数据:
- 图中 Server - 1 欲查询数据记录 1 的数据,如图中红色字体所示;
- 与 Server - 1 相关的数字 1-2 表示 IPC 请求与响应过程,其中可以将线条的斜率理解为该过程的耗时,斜率越大耗时越久;
- 绿色线条表示缓存执行数据记录查询操作的耗时,如 query cache time 所示;
- server - 1 query data process time 所代表的蓝色线条为执行本次缓存记录查询操作的总耗时;
- 缓存中不存在查询记录数据:
- 图中 Server - 2 欲查询数据记录 2 的数据,如图中红色字体所示,但缓存中不存在该数据;
- 与 Server - 2 相关的数字 1-6 表示 IPC 请求与响应过程,其中可以将线条的斜率理解为该过程的耗时,斜率越大耗时越久;
- 黑色线条表示数据库执行记录查询操作的耗时,即 i:query data time 所示;
- 蓝色线条表示应用服务执行操作耗时,如 server process time 所示,均表示收到 IPC 成功响应后准备发起后续 IPC 请求的耗时;
- 绿色线条表示缓存执行数据记录修改操作的耗时,即 iii:modify cache time 所示;
- 其中 server - 2 query data process time 所代表的蓝色线条为执行本次数据记录查询操作的总耗时;
# Cache-Aside 模式下两种数据变更实现方式
上文中提到两种实现方式最核心的区别是数据复制到缓存的时机不同。因为时机不同使得两种实现方式差异明显。接下来我们分别探讨两种实现方式。
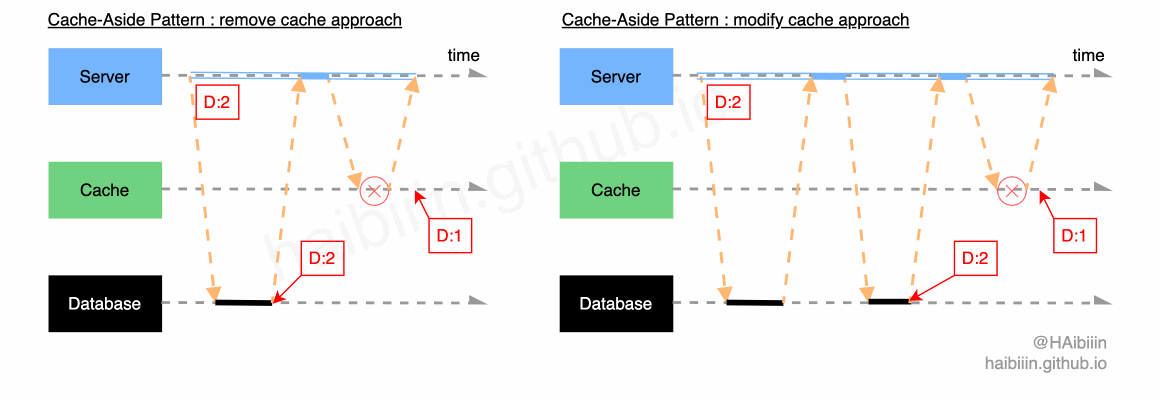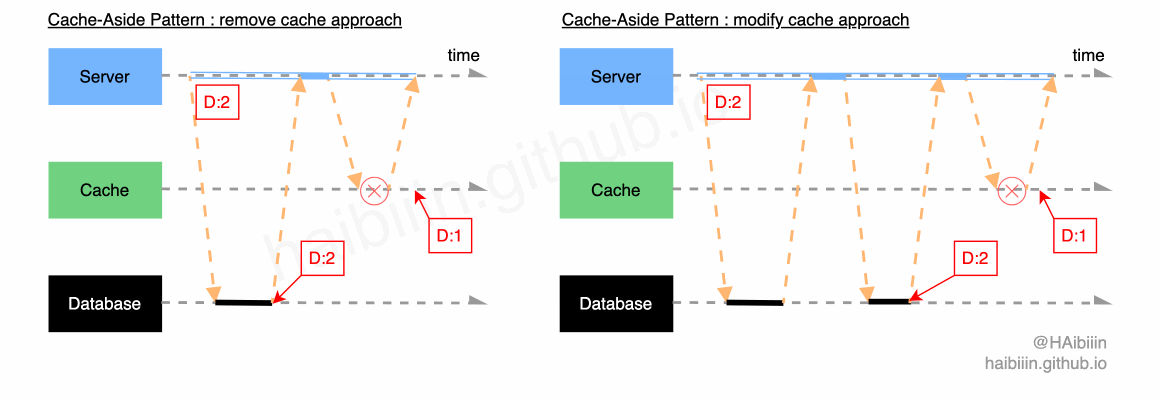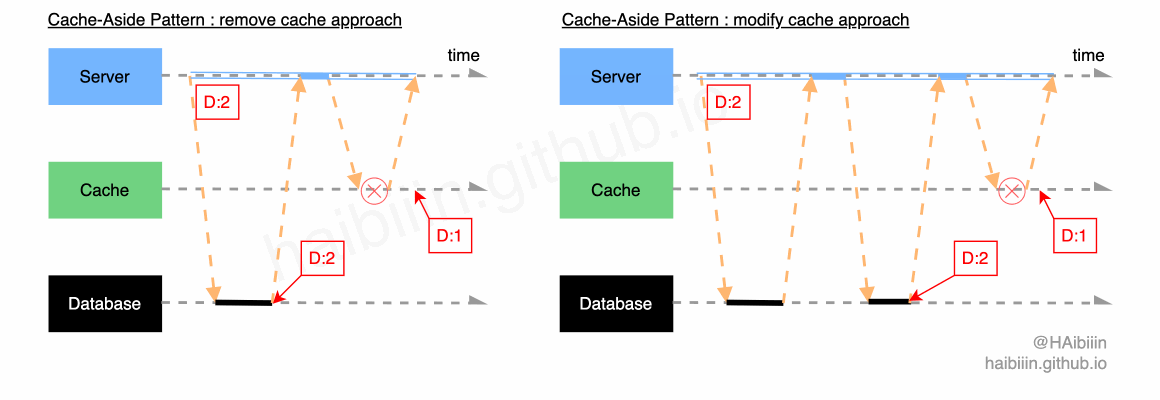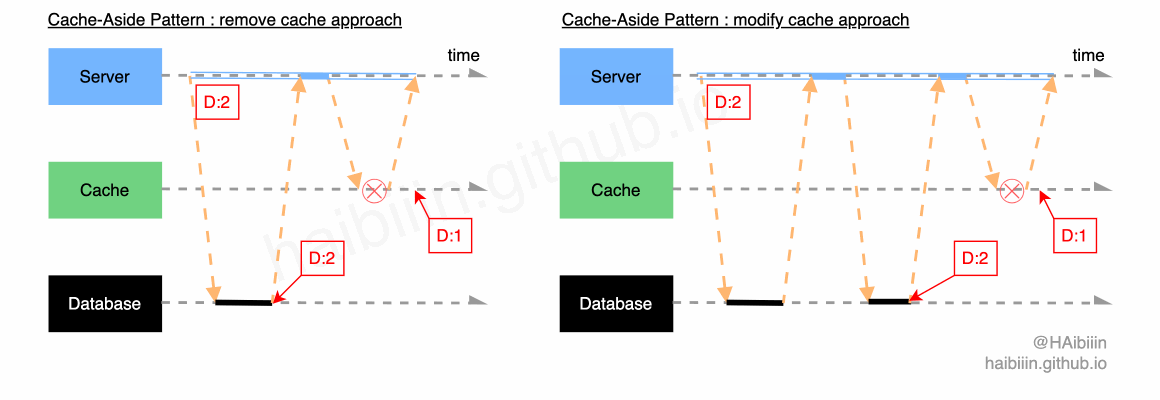
# 采取更新主副本数据后删除缓存方式
结合下方图示,删除缓存的数据变更的实现过程描述如下:
- 对于某条数据记录的变更请求到来时,应用服务先变更主副本(数据库)对应数据记录;
- 之后删除缓存中对应数据记录;
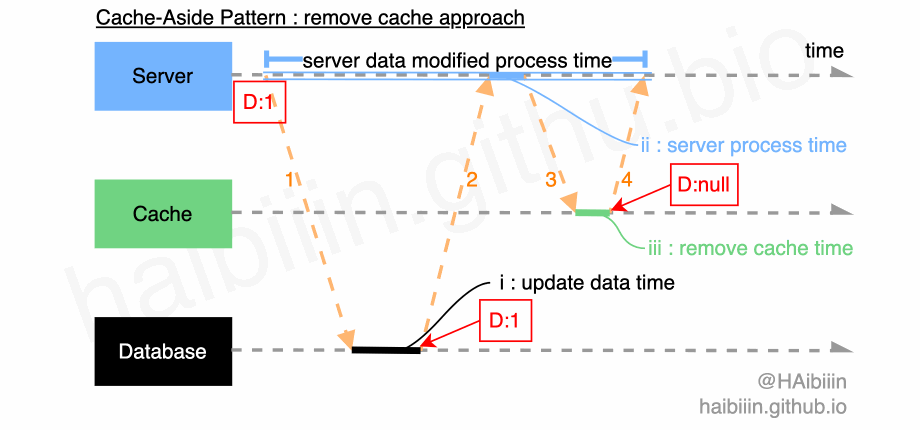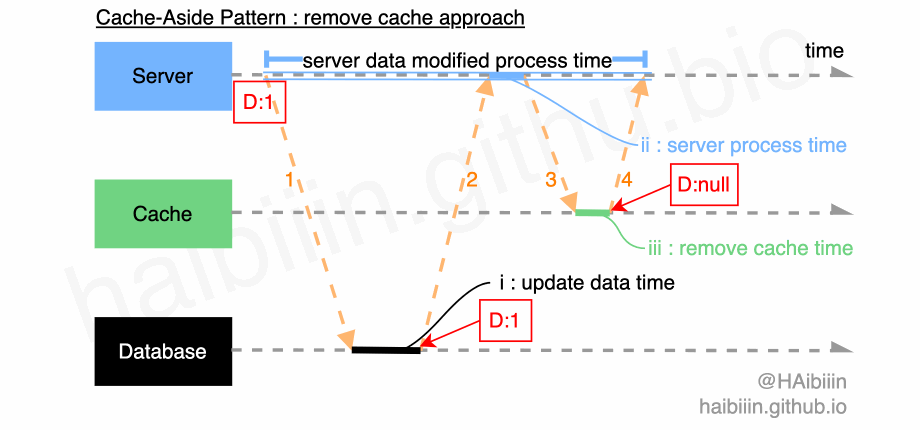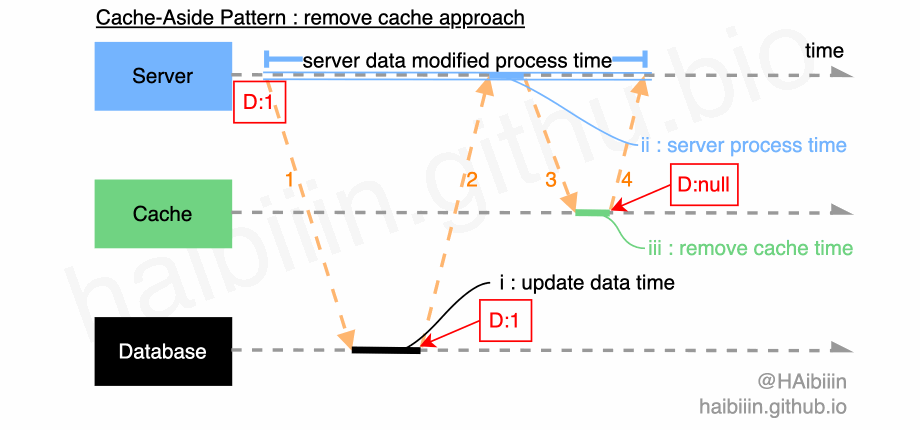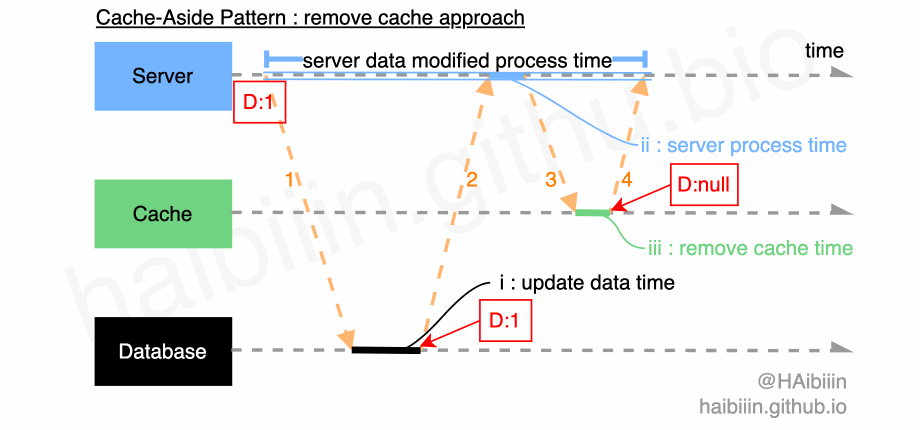
操作完成后数据库对应记录为 1,而缓存中不存在该记录值。
# 采取更新主副本数据后更新缓存方式
这里提供的方案与网络上多数文章实现略有不同,请结合下方图示,更新缓存的数据变更的实现过程描述如下:
- 对于某条数据记录的变更请求到来时,应用服务先变更主副本(数据库)对应数据记录;
- 之后再次向主副本(数据库)发起对该记录的数据查询请求(切记不可以依赖应用服务进程/内存中数据);
- 将从主副本(数据库)查询到的数据记录更新到缓存中;
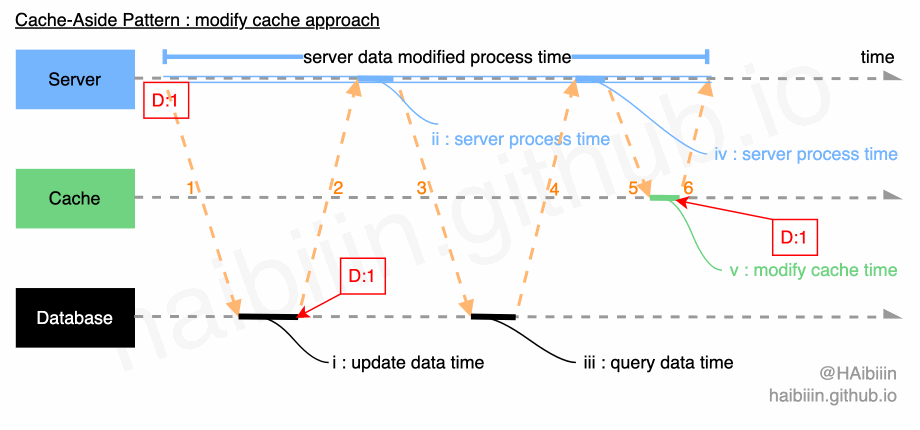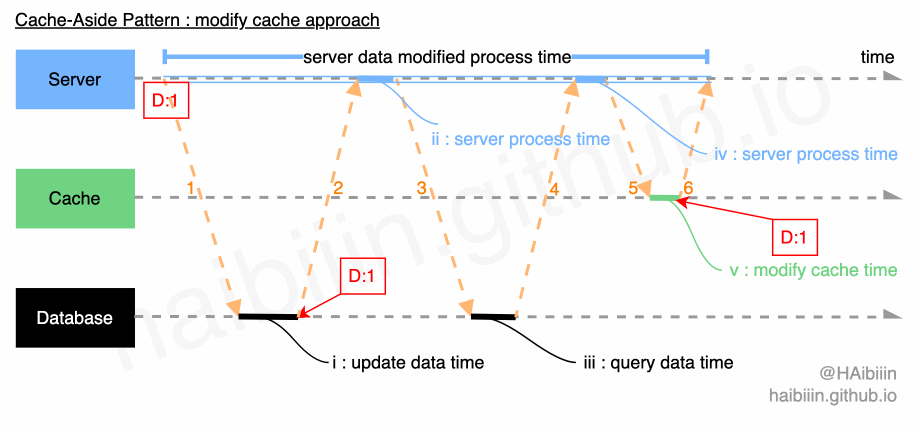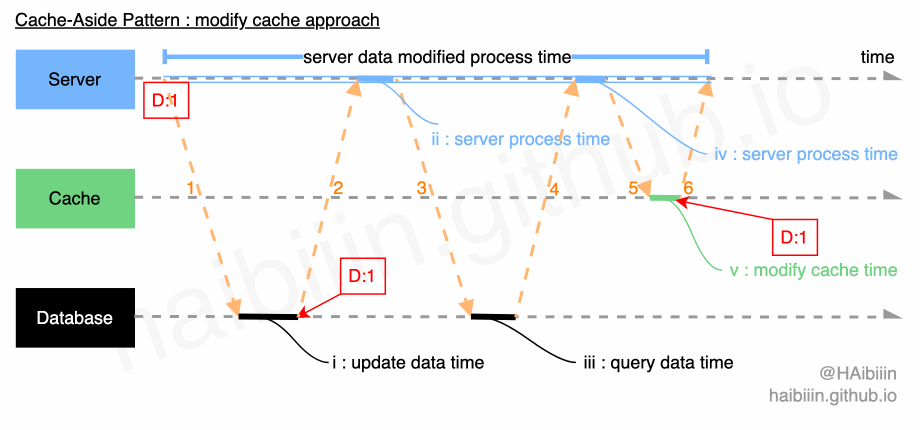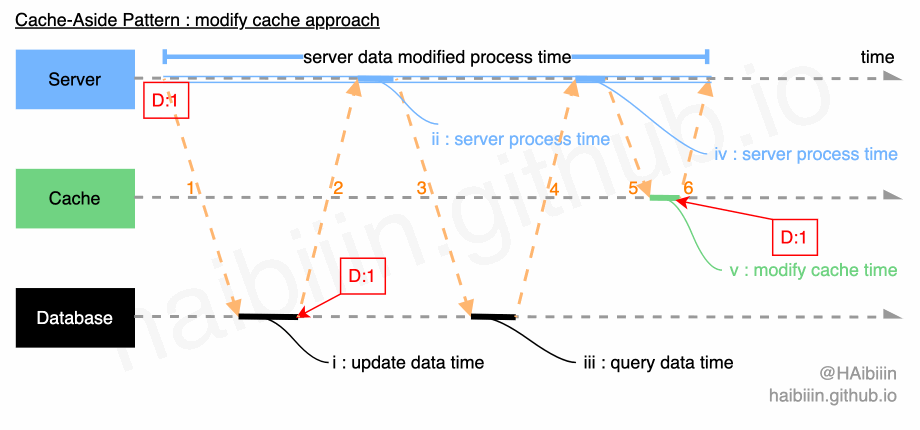
操作完成后数据库与缓存中的记录均为 1。
# 数据不一致的问题
在探讨两种实现方式孰优孰劣的争辩中,主要集中在潜在的数据不一致问题上。在前文的图示中,一直暗含着三类明显的组件。分别是代表主副本的数据库组件,以及缓存组件,余下的便是由多个实例组成的应用服务组件,这三类组件构成了一个分布式系统。
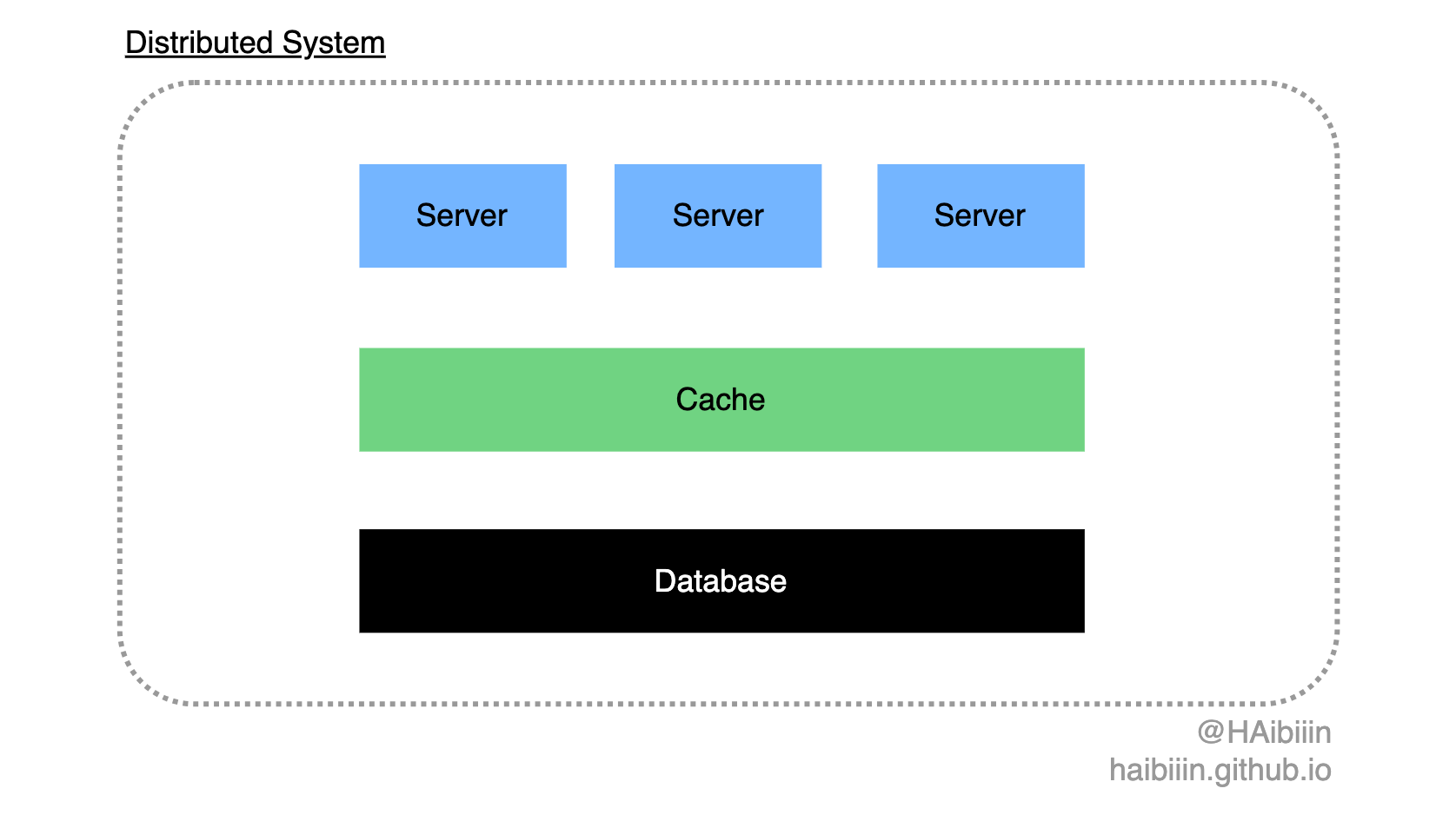
在分布式系统设计中主要面临三大挑战: 对组件并发性的支持以及克服全局时钟的缺乏和管理组件的独立失效。两种实现方式在数据变更场景下不涉及全局时钟的问题,我们围绕对组件并发性与组件独立失效,来分析两种实现方式下数据不一致的场景。
首先来看面对组件独立失效时,会产生怎样的效果。因为数据库扮演者主副本的角色,所以当数据库不可用时,可以认为整个系统是失去可用性的。此时已经无需再谈及数据一致性问题了。所以我们重点关注缓存组件失效后,会产生的效果。组件失效可能存在多种原因,这里探讨的是对缓存操作失效的情况。结合下图,分别展示了两种方式下缓存操作失效引发的数据不一致。当数据修改操作完成后,数据库中记录值已被修改为 2 ,但是在两种方式下,一种记录旧数据并未删除,另一种是未成功更新缓存中的记录值。
除了针对缓存组件操作失效外,另一种分布式挑战是面对组件的并发访问特性。在面对应用服务的并发操作时,两种实现方式依然存在导致数据不一致的情况。
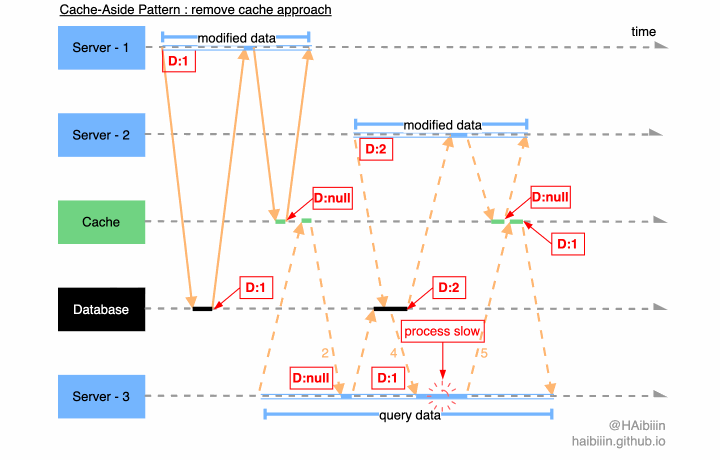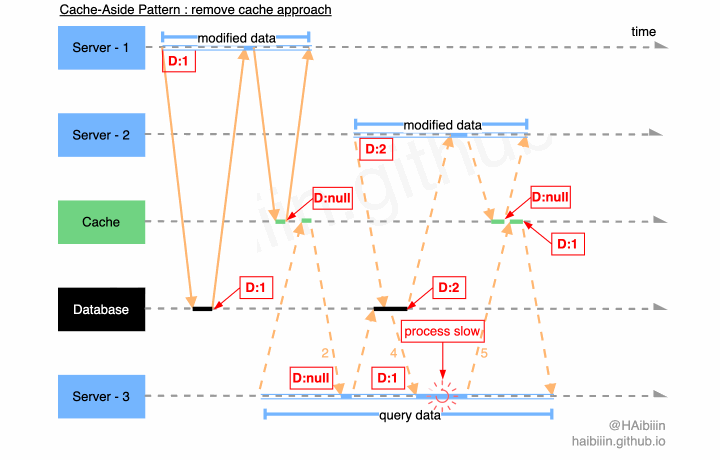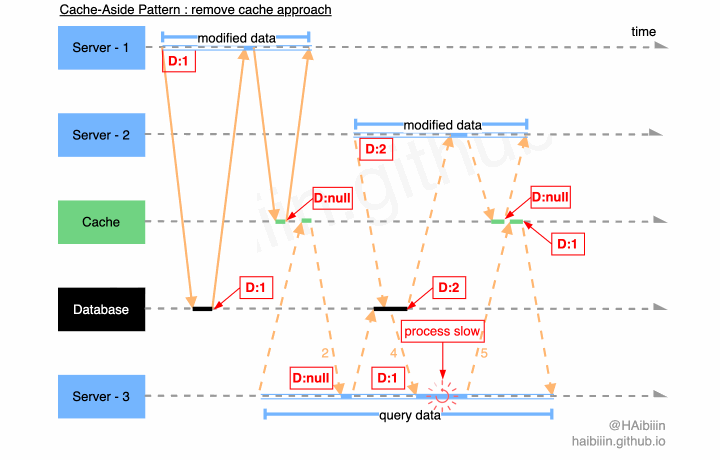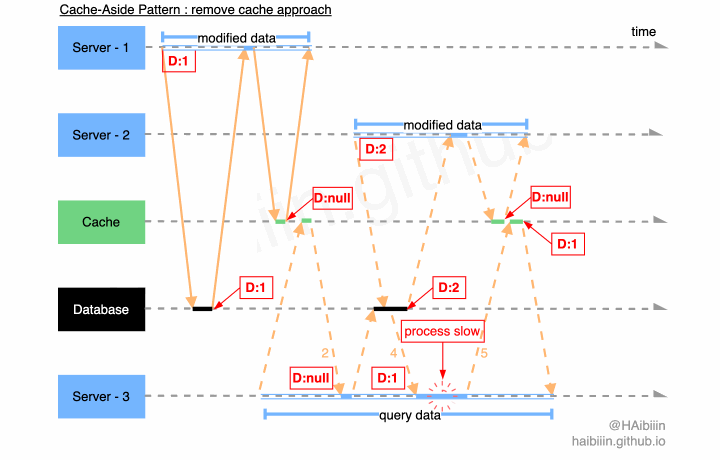
# 更新主副本数据后删除缓存方式并发访问问题
因为对于缓存的删除操作具有幂等性,所以即便是在多个应用服务并发修改的情况下,缓存数据都会以空值做为最终状态。那么会导致数据不一致的场景必然是混合了数据变更与查询的情况。
结合下面图示,系统中存在 3 个应用服务,其中服务 1-2 将同一条数据记录分别修改为 1 和 2。当 Server - 1 完成操作后,缓存中的数据已经为空值。在 Server - 2 发起数据修改前 Server - 3 执行数据查询逻辑,因为缓存中数据不存在所以从数据库中获取到记录数据为 1,并准备将其更新到缓存中。在 Server - 3 更新缓存之前 Server - 2 将记录数据更改为 2,并且在 Server - 3 更新缓存前完成了数据修改操作。如图所示 Server - 3 因为 GC 等原因导致进程/线程执行受阻,导致对缓存的更新操作滞后,将记录的历史值更新到了缓存中。最终缓存与数据主副本相同记录的数据呈现不一致的状态。
# 更新主副本数据后更新缓存方式并发访问问题
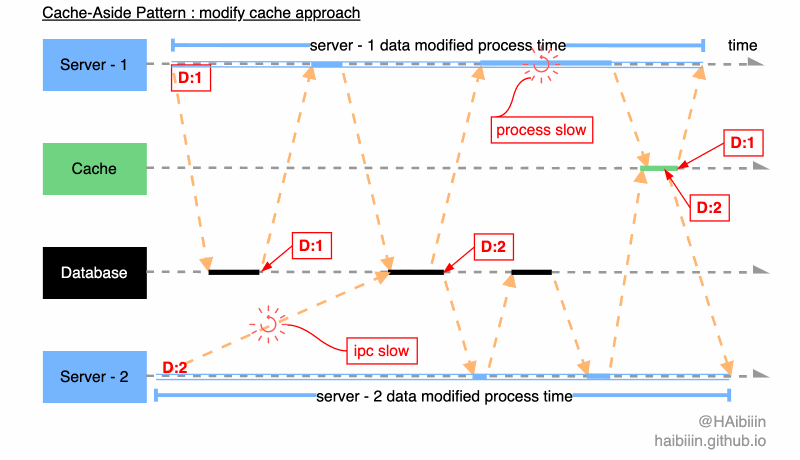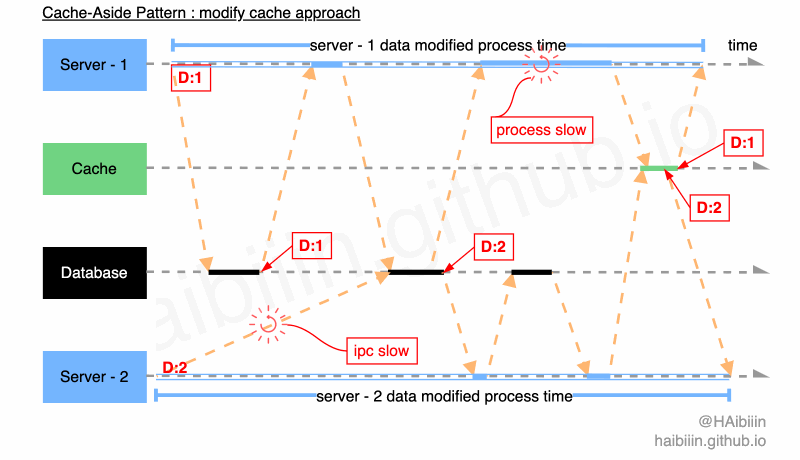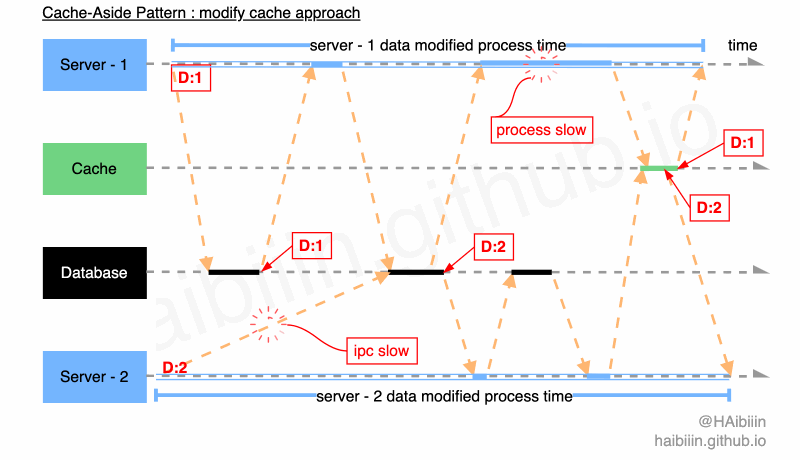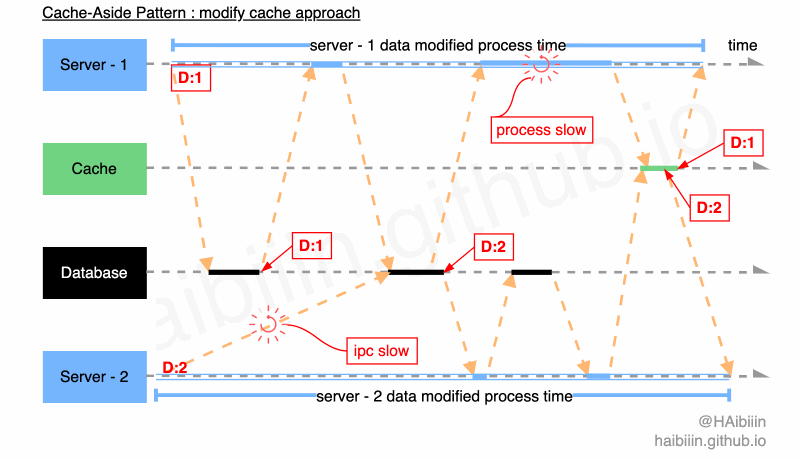
==因为数据常驻缓存,所以读请求不会影响数据一致性,问题只会发生在并发修改时。所以,本文给出的实现方式为更新完数据库后,再次获取数据库最新值可以有效降低并发情况下出现的数据不一致现象。==因数据库行级锁的存在,导致对于数据库同一条记录的修改操作必然是顺序执行逻辑。进而对于数据库记录查询操作起到了顺序约束作用,但后续操作的并发性,依然会引起数据不一致的情况。
结合下面图示,系统中存在 2 个应用服务分别将同一条数据记录修改为 1 和 2。Server - 2 因为网络原因导致执行数据更新操作较慢,在 Server - 2 完成对数据记录更新为 2 的操作前,Server - 1 已经完成数据查询操作。此时只要 Server - 2 在 Server - 1 之前完成对缓存的更新操作,便会导致缓存与主副本数据不一致的情况,如图中所示 Server - 1 因 GC 等原因导致进程/线程执行受阻,使得更新缓存操作在 Server - 2 之后完成。最终缓存与数据库主副本相同记录的数据呈现不一致的状态。
分析完两种实现方式下可能存在的数据不一致问题,不论是针对缓存操作失效导致的不一致,还是组件并发性导致的数据不一致。两种实现方式所需要采取的解决方案是一致的,我们会在下篇对如何解决一致性问题给出改进方案。
# 现阶段两种实现方式的选择
目前主流的选择都是采用删除缓存的方式,但更新缓存的方式真的不适用吗?将缓存做为数据从副本引入系统,通常都是为了解决性能与并发问题,即读多写少的场景。当数据查询请求远高于数据变更请求时,仅仅因并发修改而存在数据不一致问题的方案真的不如因查询引起数据不一致问题的方案吗?
我们上文中提到两种实现方式最核心的区别是数据复制到缓存的时机不同, 这使得两者最大的区别反而在读取场景下。删除缓存方式存在 cache miss 的情况,而更新缓存方式确保数据常驻缓存,不会发生 cache miss 的情况。所以如果你的应用在超高并发访问下,无法承受 cache miss 造成对数据库(主副本)的访问压力时,毫无疑问只能选择更新缓存的方式。不过代价则是需要更大容量的缓存存储数据,因为该方式下缓存数据是全量复制于主副本。
通常情况下,超高并发访问场景也是针对数据而言,极少会存在全量数据均处于高并发情况下。所以我们可以基于热点数据的维度,将两种模式进行结合,以换取较低的缓存容量要求。实现方式会略复杂一些,如果你感兴趣的话,请留言告诉我,我会在后续文章中探讨具体实现。
在实现复杂度上,基于本文目前讨论的内容来讲,两种方式实现复杂度几乎相同,如果要一定要区分的话更新缓存会相对复杂一点。同时删除缓存的方式还有更好语义一致性。因为当数据新增、修改和删除时,更新缓存的方式也要对应三种逻辑。
最后,两种实现方式在数据一致性等级方面均属弱一致性,所以依然存在数据不一致情况,我们会在文章后半段篇幅中给出解决不一致的方案,到时会对两者的选择再进行一次对比。如果对数据一致性要求没有那么高的话,可以基于以下表格选择适合于自身应用场景的解决方案。
| 对比内容 | 更新主副本数据后删除缓存方式 | 更新主副本数据后更新缓存方式 |
|---|---|---|
| 数据读取是否存在 cache miss | 存在 | 不存在 |
| 对缓存容量要求 | 相对较低 | 高 |
| 数据一致性等级 | 弱一致性 | 弱一致性 |
| 应用场景 | 适合一般并发访问场景,可以接受 cache miss 对主副本造成的访问 | 适合超高并发访问场景,避免出现 cache miss 的情况对主副本造成访问压力 |
| 实现复杂度 | 🌟 | 🌟🌟 |
在文章前半段篇幅中我们整理分析了 Cache-Aside 模式中数据读取与变更的实现方式。提及数据变更场景下存在 更新主副本数据后删除缓存 和 更新主副本数据后更新缓存 两种实现方式。并提出面对 缓存组件失效 与 应用服务并发访问 时数据不一致的情况,本文接下来的内容将分别针对两种情况给出设计方案。
# 应对缓存组件失效改进方案
这里我们将非编码错误导致对缓存操作失败的情况,均认为是缓存组件失效,如网络抖动导致操作失败,缓存节点下线等。首先回顾一下 更新主副本数据后删除缓存 和 更新主副本数据后更新缓存 两种方式,在面对缓存组件失效时数据不一致的情况。

通常我们在架构与运维层面会为缓存等存储系统设计主备架构,针对主节点失效后会切换为备节点,进而实现故障恢复。通常缓存组件失效属于短时性失效,应用系统需要做的便是当缓存组件恢复后,能够将此前失败的操作重新执行。
要实现此功能,最简单的方式便是通过应用服务的轮询重试。为避免对请求的阻塞,通常会启用其他的进程/线程/协程来周期性调度执行,如下图所示。
![[img-10]](https://i-blog.csdnimg.cn/direct/130b137f376646e7b31ebd45b56aae72.gif)
但是此方法虽然实现简单,但是当 Server 意外终止、宕机,其内存中的待执行的缓存操作信息也会随之丢失。同时因为轮询重试功能涵盖在应用服务代码中,如果模块依赖管理不当,代码设计不合理便会产生不必要的耦合,增加代码复杂度,增加后续业务变更复杂度。
我们可以采取将轮询重试抽取到 Batch 组件,或其他类似调度服务等组件中。同时将对缓存的操作信息通过外部持久化存储下来。由 Batch 类组件通过获取到的信息执行对应操作。此种方式可以借鉴 Outbox Pattern 来实现,具体如下图所示:
- 充当 Outbox 角色的可以是一张消息表,可以同属于业务表所在库,在同一个库的好处时利用数据库事务,确保对缓存的操作信息与业务数据一致性;
- 图中 1-2 对应的 IPC 请求为应用服务同时发起,一个事务中的操作,只不过 Outbox 表中存储为操作信息;
- Batch 组件定时轮询 Outbox 表中信息,基于获取到的新信息执行对缓存的操作,如图中 ii:query data time 所示,获取指定业务数据准备更新缓存(如果采取清理缓存实现,可以省略 query data 这一步操作);
- Batch 组件更新缓存后,“移出” 指定 Outbox 消息;

通过上述方案可以增加系统可用性,避免人工干预,缩短数据不一致时间。我们可以通过增加 Batch 组件节点,防止其单点失效。当 Batch 组件节点大于 1 个时,可以对 Outbox 中的信息加锁(如利用数据表实现乐观锁,后面会提供详细内容),避免数据重复修改。如果你所在的组织中,基础设施能力足够的话,也可以通过其他类 Pub/Sub 消息中间件来实现 Outbox。你甚至可以在 Batch 组件中将对缓存的操作进行聚类和压缩,以减少缓存变更操作次数等精细化操作等改进。
# 应对并发访问导致数据不一致改进方案
# 更新主副本数据后更新缓存并发问题解决方案
首先,结合下图回顾一下更新主副本数据后更新缓存在并发访问场景下导致数据不一致的情况。因为数据常驻缓存的因为,并发问题只存在于对数据的并发修改情况。如果我们能将并行改为串行则可以解决此类问题。

前文中给出解决缓存组件失效的改进方案,即基于 Outbox 模式实现更新主副本数据后更新缓存方式,可以避免并发更新缓存导致的数据不一致问题。我们可以通过单节点 Batch 组件可以完全避免对缓存的并发修改。
如果是多节点 Batch 组件可以利用前文中提到的数据表记录实现乐观锁,避免多节点并发修改。如图所示 Batch - 1 和 Batch - 2 通过下方的两条 SQL 争抢,最终 Batch - 1 获取到 id=xfuiea142 消息的处理权限,执行对数据记录 sku_10086 的缓存更新操作。
SELECT id, record, operate FROM outbox_message WHERE status = 'init' LIMIT 0,1;
UPDATE outbox_message SET status = 'handling' WHERE id = 'xfuiea142' AND status = 'init';

# 更新主副本数据后删除缓存并发问题解决方案
首先,结合下图回顾一下更新主副本数据后删除缓存在并发访问场景下导致数据不一致的情况。因为数据复制到缓存的时机为缓存中不存在时,所以并发问题通常发生在读写并发的场景下。

除了在上篇中给出的并发问题导致的数据不一致问题。还存在另一种情况,是由多个应用服务读请求与修改请求下造成的数据不一致,我们结合下图说明,系统初始状态,指定数据记录在数据库中值为 1,而缓存中书籍记录被删除。其中 Server - 3 率先发起数据查询,当完成数据库记录读取后,Server - 1 对该记录再次发起变更操作,随后 Server - 2 也对该记录发起查询操作,Server - 3 因为 GC 等原因导致进程/线程执行受阻。此时,在更新缓存之前,Server - 2 和 Server - 3 对该记录分别持有的值为 2 和 1。而 1 为历史旧值,但 Server - 2 先于 Server - 3完成了缓存更新操作,最终缓存与数据库中的数据呈现不一致的状态。

# 延迟双删策略可能是个糟糕的方法
至此,细心的你一定会发现,在缓存这种读多写少的场景下,上面两种数据不一致的现象,可能发生的概率要远高于更新主副本数据后更新缓存的并发问题。面对这种情况,通常的解决方案是采用简单的延迟双删策略,简单来讲是在删除缓存后间隔一定时间再次删除指定记录的缓存数据。该策略的核心依据是缓存的删除操作的幂等性,但却忽略了引起数据不一致的核心是并发问题。
产生上述现象的背后还有可能是大量读请求的到来。那么延迟双删除策略,会导致数据频繁的 cache miss 势必会造成对主副本的访问压力,也会使得缓存遭遇频繁的更新,引发系统的 thrundering herd (惊群问题)问题。
# 如何解决并发数据不一致,又能避免延迟双删带来的惊群问题
解决并发问题的出发点并不复杂,要么化解并发访问,改为非并发执行,要么为资源加锁。多年以前 Facebook(今 Meta)发表的论文 “Scaling Memcache at Facebook” 中,便通过 “leases” (这里译为“租约”)机制实现了问题的处理。
租约机制实现方法大致如下:
当有多个请求抵达缓存时,缓存中并不存在该值时会返回给客户端一个 64 位的 token ,这个 token 会记录该请求,同时该 token 会和缓存键作为绑定,该 token 即为上文中的“
leases”,其他请求需要等待这个"leases“过期后才可申请新的“leases”,客户端在更新时需要传递这个 token ,缓存验证通过后会进行数据的存储。
具体过程,我们可以结合上文中给出的数据不一致案例来理解。Server - 3 查询缓存中不存在记录数据,获取租约 leases:x01 ,同时在缓存中该租约信息与对应记录绑定,之后 Server - 3 执行后续逻辑。Server - 2 执行数据更新操作,删除缓存的过程中此前保存的租约信息也被连带删除。但 Server - 3 尝试更新缓存前,需要和缓存比对租约信息发现 leases:x01 与缓存当前租约(当前租约已不存在)不匹配,于是重新获取租约 leases:x02,并再次执行对数据库的查询逻辑,最后完成缓存数据更新操作。

我们继续分析对另一个数据不一致场景的应用。Server - 3 查询缓存中不存在记录数据,获取租约 leases:x01 ,同时在缓存中该租约信息与对应记录绑定,之后 Server - 3 执行后续逻辑。Server - 1 执行数据更新操作,删除缓存的过程中此前保存的租约信息也被连带删除。Server - 2 查询缓存中不存在记录数据,获取租约 leases:x02 ,同时在缓存中该租约信息与对应记录绑定,之后 Server - 2 执行后续逻辑。Server - 2 在更新缓存时检查租约信息与 leases:x02 匹配,完成缓存数据更新并清理租约。之后 Server - 3 带着过期租约 leases:x01 尝试更新缓存,因缓存租约不匹配且记录有数据,则放弃更新直接读取缓存记录数据。

通过上述分析,我们可以发现租约机制可以解决并发问题带来的数据不一致,但是要如何处理惊群问题呢?我们结合下图进一步分析,三个应用服务 Server 1-3 分别发起数据查询请求,其中 Server - 1 先查询缓存中不存在记录数据,获取租约 leases:x01 ,同时在缓存中该租约信息与对应记录绑定。之后 Server - 2 与 3 查询缓存记录,获取到租约信息后分别等待 3ms 再向缓存发起查询请求。期间 Server - 1 完成对数据库的查询,并通过缓存的租约验证成功更新缓存,此时缓存中已经有了记录数据。Server - 2 与 3再次发起请求时便可以直接获取缓存数据返回。

# 附:Redis 实现 Leases 机制
要想为 Redis 添加 Leases 机制,需要结合 Lua 脚本来实现,Lua 脚本代码示例如下:
local key = KEYS[1]
local token = ARGV[1]
local value = redis.call('get', key)
if not value then
redis.replicate_commands()
local lease_key = 'lease:'..key
redis.call('set', lease_key, token)
return {false, false}
else
return {value, true}
end
为了与业务数据作区分,脚本中将业务存储键增加了 lease: 前缀,后续可以对指定前缀的键值数据作清理,也可以在上述脚本中对 lease: 前缀数据增加过期时间。
这里返回值对于客户端来讲变成了一个数组,需要对数组中的值进行逻辑判断处理,根据 token 有值的情况进行等待与重试处理。同样对于缓存数据的设置,也不能直接使用 Redis 的指令,需要配合 Lua 脚本实现 token 检查机制,Lua 脚本代码示例如下:
local key = KEYS[1]
local token = ARGV[1]
local value = ARGV[2]
local lease_key = 'lease:'..key
local lease_value = redis.call('get', lease_key)
if lease_value == token then
redis.replicate_commands()
redis.call('set', key, value)
return {value, true}
else
return {false, false}
end
通过上述脚本可以发现,以上操作增加了数据处理复杂度。主要表现为缓存模型的变化,需要应用端做适配改造。在实际制定方案时需根据实际情况,判定是否采用上述方案保证严格的一致性。
# 两种实现方式的选择
至此关于缓存与主副本数据一致性系统设计算是拥有完整的解决方案。为应对缓存组件失效我们需要独立出 Batch 类组件,进行缓存操作的轮询重试。为进一步解决并发问题我们必须利用 “锁” 的机制。基于上文中给出的方案,我们会发现为了解决更新主副本后删除缓存方式的两个问题,技术实现复杂度与成本其实要高于更新主副本后更新缓存方式。但删除缓存方式在缓存空间要求上有着巨大优势。所以最终要根据实际场景下,各方因素的考量进行选择。
| 对比内容 | 更新主副本数据后删除缓存方式 | 更新主副本数据后更新缓存方式 |
|---|---|---|
| 数据读取是否存在 cache miss | 存在 | 不存在 |
| 对缓存容量要求 | 相对较低 | 高 |
| 数据一致性等级 | 弱一致性 | 弱一致性 |
| 应用场景 | 适合一般并发访问场景,可以接受 cache miss 对主副本造成的访问 | 适合超高并发访问场景,避免出现 cache miss 的情况对主副本造成访问压力 |
| 实现复杂度 | 🌟 | 🌟🌟 |
| 数据一致性提升方案实现复杂度 | 🌟🌟🌟🌟 | 🌟🌟🌟 |
不过我们依然可以得出一个结论,当需要缓存的数据量不大,且存在超高并发访问的场景下,并且对数据一致性要求较高的背景下,可以采用改进后更新主副本后更新缓存方式。而潜在缓存数据量较大,同样存在超高并发访问的场景下,并且对数据一致性要求较高的背景下,可以采用改进后更新主副本后删除缓存方式。
| 缓存容量需求 | 并发数量支持 | 数据一致性延迟容忍 | |
|---|---|---|---|
| 更新主副本数据后删除缓存方式 | 低 | 高 | 一般 |
| 更新主副本数据后更新缓存方式 | 高 | 超高 | 一般 |
| 针对数据一致性问题改进后,更新主副本数据后删除缓存方式 | 低 | 超高 | 较低 |
| 针对数据一致性问题改进后,改进后更新主副本数据后更新缓存方式 | 高 | 超高 | 较低 |